如何最大化利用Youtube shorts流量,python自动化脚本教程,躺赚美金
这是一个在blackhat论坛售卖的教程,50美金,有python编程经验可以尝试,经过本人测试可以使用
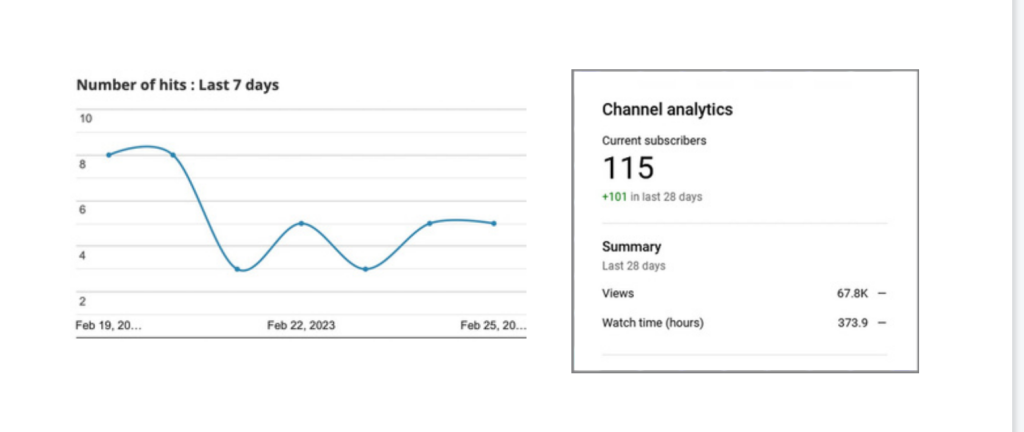
在本指南中,你将学习如何从以下方面获得免费流量,以及如何用Python将这一过程自动化。
有无数种不同的方法来使各种变化,以及寻找不同的利基和货币化选项。
本指南的目的是要展示如何实现一个完全自动化和免费的流量源。它不打算让你复制这本电子书中的方法
作为例子显示在这本电子书中。这不是一个赚钱的指南,而是一个经过充分研究的流量方法与货币化的想法。本指南中分享的所有代码,都是经过测试的,并且在发布之初就能正常使用。有可能未来,YouTube的算法可能会发生变化,所以请理解,你可能需要调整这些代码。
YouTube不喜欢自动频道,并且经常对上传过程进行修改。如果上传脚本已经停止工作,请联系本人(微信:15510609736)
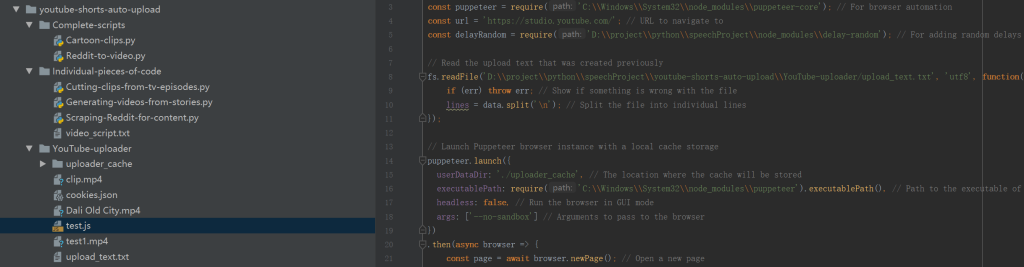
链接:https://pan.baidu.com/s/1TUl6TniXtxAJCt5Bx6XcEw?pwd=0kqa
单独的代码片断:
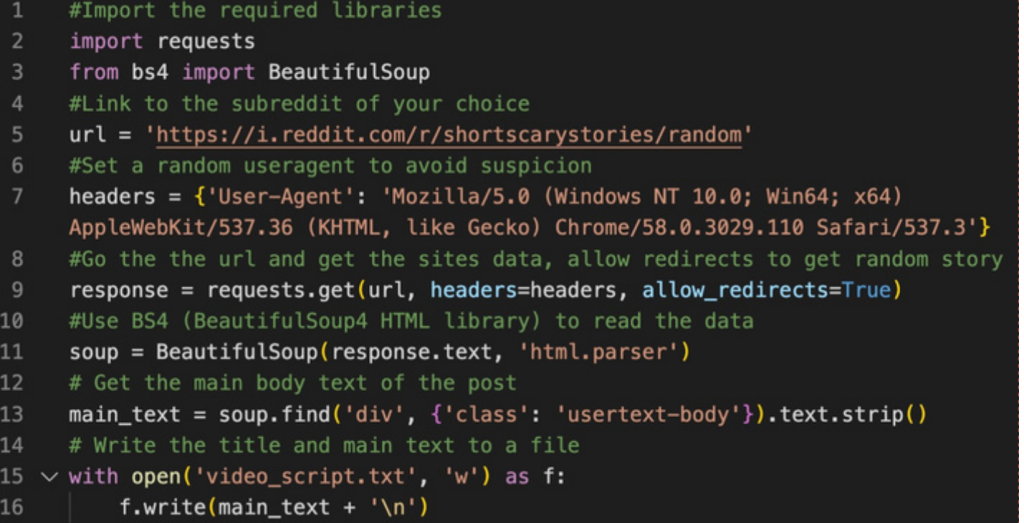
Scraping Reddit for content:
#Import the required libraries
import requests
from bs4 import BeautifulSoup
#Link to the subreddit of your choice
url = 'https://i.reddit.com/r/shortscarystories/random'
#Set a random useragent to avoid suspicion
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
#Go the the url and get the sites data, allow redirects to get random story
response = requests.get(url, headers=headers, allow_redirects=True)
#Use BS4 (BeautifulSoup4 HTML library) to read the data
soup = BeautifulSoup(response.text, 'html.parser')
# Get the main body text of the post
main_text = soup.find('div', {'class': 'usertext-body'}).text.strip()
# Write the title and main text to a file
with open('video_script.txt', 'w') as f:
f.write(main_text + '\n')
Generating videos from stories:
# Import the necessary libraries and modules
import nltk # for natural language processing tasks
import datetime # for date and time manipulation
from TTS.api import TTS # text to speech package
from moviepy.editor import * # video editing package
from nltk.tokenize import sent_tokenize # sentence tokenization from natural language
from moviepy.video.tools.subtitles import SubtitlesClip # tools for reading and displaying subtitles
# Download the 'punkt' module used for sentence tokenization if it has not already been downloaded
nltk.download('punkt')
# Select the model for text-to-speech conversion
model_name = TTS.list_models()[12]
# Create an instance of the selected text-to-speech model
tts = TTS(model_name)
# Open the text file containing the video script, and read the contents
video_script = open('video_script.txt', 'r').read()
# Convert the video script to an audio file using the selected text-to-speech model
tts.tts_to_file(text=video_script, file_path="voiceover.wav")
# Load the newly created audio file, and adjust the volume of the background music
new_audioclip = CompositeAudioClip([
AudioFileClip("voiceover.wav"),
AudioFileClip('background_music.mp3').volumex(0.2)
])
# Load the video file that will be used as the background of the final clip
video = VideoFileClip('background_video.mp4')
# Determine the dimensions of the video, and calculate the desired width based on the aspect ratio of 16:9
width, height = video.size
new_width = int(height * 9/16)
# Crop the video to the desired width, centered horizontally
clip = video.crop(x1=(width - new_width) / 2, x2=(width - new_width) / 2 + new_width)
# Set the audio of the cropped video to the adjusted background music and voiceover audio
clip.audio = new_audioclip
# Define a function to create subtitles for the video
def subtitles(sentences):
# Initialize an empty list to store the SRT file contents
srt_lines = []
# Initialize the start and end time to zero
start = datetime.timedelta(seconds=0)
end = datetime.timedelta(seconds=0)
# Initialize a counter to keep track of subtitle numbers
counter = 1
# Loop over each sentence in the list of sentences passed to the function
for sentence in sentences:
# Split the sentence into words
words = sentence.split()
# Calculate the number of lines needed for this sentence (assuming each line has 4 words)
num_lines = len(words) // 4 + 1
# Loop over each line of the sentence
for j in range(num_lines):
# Get the words for this line
line_words = words[j * 4: (j + 1) * 4]
# Join the words into a single string to form the line
line = ' '.join(line_words)
# Calculate the end time for this line based on the length of the line
end += datetime.timedelta(seconds=len(line_words) * 0.35)
# Check if the line is not empty
if line:
# Format the start and end times as strings in the SRT format
start_str = '{:02d}:{:02d}:{:02d},{:03d}'.format(
start.seconds // 3600,
(start.seconds // 60) % 60,
start.seconds % 60,
start.microseconds // 1000
)
end_str = '{:02d}:{:02d}:{:02d},{:03d}'.format(
end.seconds // 3600,
(end.seconds // 60) % 60,
end.seconds % 60,
end.microseconds // 1000
)
# Add the subtitle number, start and end times, and line to the SRT list
srt_lines.append(str(counter))
srt_lines.append(start_str + ' --> ' + end_str)
srt_lines.append(line)
srt_lines.append('')
# Increment the subtitle counter
counter += 1
# Update the start time for the next line
start = end
# Join the lines of the SRT file into a single string
srt_file = '\n'.join(srt_lines)
# Write the SRT file to disk
with open("subtitles.srt", "w") as f:
f.write(srt_file)
# Call the 'subtitles' function with a list of sentences, which are obtained by tokenizing the video script
subtitles(list(filter(None, (sent_tokenize(video_script)))))
# Define a lambda function to generate the subtitle clips from the SRT file
generator = lambda txt: TextClip(txt, font='Arial-Bold', fontsize=20, color='white', bg_color='rgba(0,0,0,0.4)')
# Create the subtitle clip from the SRT file
subtitle_source = SubtitlesClip("subtitles.srt", generator)
# Combine the video clip and the subtitle clip, and adjust the speed and length of the result
clip = CompositeVideoClip([clip, subtitle_source.set_pos(('center', 400))]).speedx(factor=1.1).subclip(0, 60)
# Write the final video clip to disk
clip.write_videofile("clip.mp4")
Cutting clips from tv episodes:
import os # importing os module for interacting with operating system
import random # importing random module for generating random values
from moviepy.editor import * # importing necessary classes from moviepy module
from moviepy.video.VideoClip import TextClip
# creating a list of .mp4 files in the 'Episodes' directory using list comprehension
mp4_files = [file for file in os.listdir('Episodes') if file.endswith('.mp4')]
# randomly choosing a file from the list
random_file = random.choice(mp4_files)
# creating the full path of the chosen video file
video_file = os.path.join('Episodes', random_file)
# loading the video file using VideoFileClip() class
video = VideoFileClip(video_file)
# getting the duration of the video
duration = video.duration
# choosing a random start time between 30 seconds and 60 seconds before the end of the video
start = random.uniform(30, max(30, duration - 60))
# choosing a random length between 20 seconds and 40 seconds
lenght = random.randint(20, 40)
# extracting the clip from the video using the chosen start time and length
clip = video.subclip(start, start + lenght)
# getting the width and height of the clip
width, height = clip.size
# calculating the aspect ratio of the clip
aspect_ratio = width / height
# calculating the new width of the clip with a 16:9 aspect ratio
new_width = int(height * 9/16)
# calculating the left margin to center the clip horizontally
left_margin = (width - new_width) / 2
# cropping the clip to the new width and centering it horizontally
clip = clip.crop(x1=left_margin, x2=left_margin + new_width)
# increasing the speed of the clip by 10%
clip = clip.speedx(factor=1.1)
# flipping the clip horizontally
clip = clip.fx(vfx.mirror_x)
# creating a TextClip object with the desired text and properties
text = "Surprise in comments\nEnter & WIN!"
txt_clip = TextClip(text, fontsize=15, color='white', font='Arial-Bold')
# setting the position of the text clip to be centered near the bottom of the screen
txt_clip = txt_clip.set_position(('center', 0.8), relative=True)
# creating a CompositeVideoClip object by combining the clip and text clip
final_clip = CompositeVideoClip([clip, txt_clip])
# setting the duration of the final clip to be the same as the cropped clip
final_clip.duration = clip.duration
# writing the final clip to a file named 'clip.mp4'
final_clip.write_videofile("clip.mp4")
完整脚本:
Reddit to video:
# Import the necessary libraries and modules
import nltk # for natural language processing tasks
import datetime # for date and time manipulation
import requests # for scraping reddit
from bs4 import BeautifulSoup # for reading html
from TTS.api import TTS # text to speech package
from moviepy.editor import * # video editing package
from nltk.tokenize import sent_tokenize # sentence tokenization from natural language
from moviepy.video.tools.subtitles import SubtitlesClip # tools for reading and displaying subtitles
# Download the 'punkt' module used for sentence tokenization if it has not already been downloaded
nltk.download('punkt')
#Link to the subreddit of your choice
url = 'https://i.reddit.com/r/shortscarystories/random'
#Set a random useragent to avoid suspicion
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
#Go the the url and get the sites data, allow redirects to get random story
response = requests.get(url, headers=headers, allow_redirects=True)
#Use BS4 (BeautifulSoup4 HTML library) to read the data
soup = BeautifulSoup(response.text, 'html.parser')
# Get the main body text of the post
main_text = soup.find('div', {'class': 'usertext-body'}).text.strip()
# Write the title and main text to a file
with open('video_script.txt', 'w') as f:
f.write(main_text + '\n')
# Select the model for text-to-speech conversion
model_name = TTS.list_models()[12]
# Create an instance of the selected text-to-speech model
tts = TTS(model_name)
# Open the text file containing the video script, and read the contents
video_script = open('video_script.txt', 'r').read()
# Convert the video script to an audio file using the selected text-to-speech model
tts.tts_to_file(text=video_script, file_path="voiceover.wav")
# Load the newly created audio file, and adjust the volume of the background music
new_audioclip = CompositeAudioClip([
AudioFileClip("voiceover.wav"),
AudioFileClip('background_music.mp3').volumex(0.2)
])
# Load the video file that will be used as the background of the final clip
video = VideoFileClip('background_video.mp4')
# Determine the dimensions of the video, and calculate the desired width based on the aspect ratio of 16:9
width, height = video.size
new_width = int(height * 9/16)
# Crop the video to the desired width, centered horizontally
clip = video.crop(x1=(width - new_width) / 2, x2=(width - new_width) / 2 + new_width)
# Set the audio of the cropped video to the adjusted background music and voiceover audio
clip.audio = new_audioclip
# Define a function to create subtitles for the video
def subtitles(sentences):
# Initialize an empty list to store the SRT file contents
srt_lines = []
# Initialize the start and end time to zero
start = datetime.timedelta(seconds=0)
end = datetime.timedelta(seconds=0)
# Initialize a counter to keep track of subtitle numbers
counter = 1
# Loop over each sentence in the list of sentences passed to the function
for sentence in sentences:
# Split the sentence into words
words = sentence.split()
# Calculate the number of lines needed for this sentence (assuming each line has 4 words)
num_lines = len(words) // 4 + 1
# Loop over each line of the sentence
for j in range(num_lines):
# Get the words for this line
line_words = words[j * 4: (j + 1) * 4]
# Join the words into a single string to form the line
line = ' '.join(line_words)
# Calculate the end time for this line based on the length of the line
end += datetime.timedelta(seconds=len(line_words) * 0.35)
# Check if the line is not empty
if line:
# Format the start and end times as strings in the SRT format
start_str = '{:02d}:{:02d}:{:02d},{:03d}'.format(
start.seconds // 3600,
(start.seconds // 60) % 60,
start.seconds % 60,
start.microseconds // 1000
)
end_str = '{:02d}:{:02d}:{:02d},{:03d}'.format(
end.seconds // 3600,
(end.seconds // 60) % 60,
end.seconds % 60,
end.microseconds // 1000
)
# Add the subtitle number, start and end times, and line to the SRT list
srt_lines.append(str(counter))
srt_lines.append(start_str + ' --> ' + end_str)
srt_lines.append(line)
srt_lines.append('')
# Increment the subtitle counter
counter += 1
# Update the start time for the next line
start = end
# Join the lines of the SRT file into a single string
srt_file = '\n'.join(srt_lines)
# Write the SRT file to disk
with open("subtitles.srt", "w") as f:
f.write(srt_file)
# Call the 'subtitles' function with a list of sentences, which are obtained by tokenizing the video script
subtitles(list(filter(None, (sent_tokenize(video_script)))))
# Define a lambda function to generate the subtitle clips from the SRT file
generator = lambda txt: TextClip(txt, font='Arial-Bold', fontsize=20, color='white', bg_color='rgba(0,0,0,0.4)')
# Create the subtitle clip from the SRT file
subtitle_source = SubtitlesClip("subtitles.srt", generator)
# Combine the video clip and the subtitle clip, and adjust the speed and length of the result
clip = CompositeVideoClip([clip, subtitle_source.set_pos(('center', 400))]).speedx(factor=1.1).subclip(0, 60)
# Write the final video clip to disk
clip.write_videofile("clip.mp4")
pos1 = ['Entry1', 'Entry2']
pos2 = ['Entry1', 'Entry2']
with open("count.txt", 'r') as file:
counter = file.read()
title = f"Horror Story {random.choice(pos1)} #{counter} ({os.path.splitext(random_file)[0]})\n"
description = f"""{random.choice(pos2)} subscribe for more {os.path.splitext(random_file)[0]} | Special offer: yourcpalink
#tag1, #tag1, #tag3
"""
tag_list = ["tag1", "tag2", "tag3"]
tags = random.choice(tag_list)+','+random.choice(tag_list)+','+random.choice(tag_list)
with open("video_text.txt", 'w') as file:
file.write(title+description+tags)
execute_js('upload.js')
Cartoon clips:
import os # Import the os module to handle file operations
import random # Import the random module to generate random numbers
from moviepy.editor import * # Import the necessary classes from the moviepy module
from moviepy.video.VideoClip import TextClip
from Naked.toolshed.shell import execute_js, muterun_js # Import execute_js and muterun_js from Naked.toolshed.shell
mp4_files = [file for file in os.listdir('Episodes') if file.endswith('.mp4')] # Get all the .mp4 files in the Episodes directory
random_file = random.choice(mp4_files) # Choose a random file from the list
video_file = os.path.join('Episodes', random_file) # Construct the file path of the chosen video
video = VideoFileClip(video_file) # Create a VideoFileClip object from the chosen video file
duration = video.duration # Get the duration of the video in seconds
start = random.uniform(30, max(30, duration - 60)) # Choose a random starting time for the clip
length = random.randint(20, 40) # Choose a random length for the clip
clip = video.subclip(start, start + length) # Create a subclip from the chosen start time and length
width, height = clip.size # Get the width and height of the clip
aspect_ratio = width / height # Calculate the aspect ratio of the clip
new_width = int(height * 9/16) # Calculate the new width of the clip based on a 16:9 aspect ratio
left_margin = (width - new_width) / 2 # Calculate the left margin needed to center the clip horizontally
clip = clip.crop(x1=left_margin, x2=left_margin + new_width) # Crop the clip to the new dimensions
clip = clip.speedx(factor=1.1) # Speed up the clip by 10%
clip = clip.fx(vfx.mirror_x) # Apply a mirror effect to the clip
text = "Surprise in comments!\nSubscribe for more" # Create the text to display in the video
txt_clip = TextClip(text, fontsize=15, color='white', font='Arial-Bold') # Create a TextClip object with the specified text
txt_clip = txt_clip.set_position(('center', 0.8), relative=True) # Set the position of the text relative to the center of the clip
final_clip = CompositeVideoClip([clip, txt_clip]) # Create a composite clip with the video clip and the text clip
final_clip.duration = clip.duration # Set the duration of the final clip to match the duration of the video clip
final_clip.write_videofile("clip.mp4") # Save the final clip as a new video file
pos1 = ['Entry1', 'Entry2'] # List of possible values for position 1 in the video title
pos2 = ['Entry1', 'Entry2'] # List of possible values for position 2 in the video description
with open("count.txt", 'r') as file: # Open the count.txt file for reading
counter = file.read() # Read the current value of the counter from the file
title = f"Funny Cartoon {random.choice(pos1)} #{counter} ({os.path.splitext(random_file)[0]})\n" # Construct the video title
description = f"""{random.choice(pos2)} subscribe for more {os.path.splitext(random_file)[0]} | Special offer: yourcpalink
#tag1, #tag1, #tag3
"""
tag_list = ["tag1", "tag2", "tag3"]
tags = random.choice(tag_list)+','+random.choice(tag_list)+','+random.choice(tag_list)
with open("video_text.txt", 'w') as file:
file.write(title+description+tags)
# Execute a JavaScript file called "upload.js" to upload the video to YouTube
execute_js('upload.js')
# Increment a counter in a file called "count.txt" to keep track of the number of videos uploaded
with open("count.txt", 'r') as file:
counter = int(file.read())
counter += 1
with open("count.txt", 'w') as file:
file.write(str(counter))
YouTube uploader:
Video upload:
// Import required packages const fs = require('fs'); // For reading files const puppeteer = require('puppeteer-core'); // For browser automation const url = 'https://studio.youtube.com/'; // URL to navigate to const delayRandom = require('delay-random'); // For adding random delays // Read the upload text that was created previously fs.readFile('upload_text.txt', 'utf8', function(err, data) { if (err) throw err; // Show if something is wrong with the file lines = data.split('\n'); // Split the file into individual lines }); // Launch Puppeteer browser instance with a local cache storage puppeteer.launch({ userDataDir: './uploader_cache', // The location where the cache will be stored executablePath: require('puppeteer').executablePath(), // Path to the executable of a specific version of Chrome (installed by Puppeteer) headless: false, // Run the browser in GUI mode args: ['--no-sandbox'] // Arguments to pass to the browser }) .then(async browser => { const page = await browser.newPage(); // Open a new page await page.setCacheEnabled(true); // Enable the cache to save the sessions await page.setViewport({ width: 1280, height: 720 }); // Set the size for the browser window // Read the cookies from a JSON file const cookies = JSON.parse(fs.readFileSync('cookies.json', 'utf8')); // Add the cookies to the page for (const cookie of cookies) { await page.setCookie(cookie); } await page.goto(url); // Go to the YouTube Studio website await delayRandom(14000, 26000); // Wait for the website to load (adjust based on your internet speed) // From this point on, the script interacts with the website by clicking buttons and entering text await page.click('#create-icon'); // Click on the 'Create' button await delayRandom(1000, 2000); // Wait for the next step to load await page.click('#text-item-0'); // Click on the 'Text' option await delayRandom(1000, 2000); // Wait for the next step to load await page.click('#select-files-button'); // Click on the 'Select files' button await delayRandom(1000, 2000); // Wait for the next step to load const elementHandle = await page.$("input[type=file]"); // Get the file input element await elementHandle.uploadFile('clip.mp4'); // Upload the video file (make sure everything is in the same folder) await delayRandom(8000, 10000); // Wait for the file to upload (adjust based on your file size) await page.keyboard.type(lines[0], {delay: 150}); // Enter the title of the video await delayRandom(1000, 2000); // Wait for the next step to load await page.keyboard.press('Tab'); // Move to the next input field await delayRandom(500, 600); // Wait for the next step to load await page.keyboard.press('Tab'); // Move to the next input field await delayRandom(1000, 2000); // Wait for the next step to load await page.focus('#description-container'); //focus on the description container await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.type(lines[1], {delay: 150}); //type the first line of the description with a delay between keystrokes await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.type(lines[2], {delay: 150}); //type the second line of the description with a delay between keystrokes await delayRandom(1000, 2000); //wait for a random amount of time await page.click('#audience > ytkc-made-for-kids-select > div.made-for-kids-rating-container.style-scope.ytkc-made-for-kids-select > tp-yt-paper-radio-group > tp-yt-paper-radio-button:nth-child(2)'); //click the "No, it's not made for kids" radio button await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.press('Tab'); //press the Tab key await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.press('Tab'); //press the Tab key again await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.press('Enter'); //press the Enter key await delayRandom(1000, 2000); //wait for a random amount of time for (let i = 0; i < 8; i++) { //loop 8 times await page.keyboard.press('Tab'); //press the Tab key await delayRandom(300, 600); //wait for a random amount of time } await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.type(lines[3], {delay: 150}); //type the third line of the description with a delay between keystrokes await delayRandom(1000, 2000); //wait for a random amount of time await page.click('#next-button'); //click the "Next" button await delayRandom(1000, 2000); //wait for a random amount of time await page.click('#next-button'); //click the "Next" button again await delayRandom(1000, 2000); //wait for a random amount of time await page.click('#next-button'); //click the "Next" button a third time await delayRandom(1000, 2000); //wait for a random amount of time await page.click('#offRadio'); //click the "Not made for kids" radio button await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.press('Tab'); //press the Tab key await delayRandom(1000, 2000); //wait for a random amount of time await page.keyboard.press('ArrowUp'); //press the Up Arrow key await delayRandom(15000, 20000); //wait for a random amount of time await page.click('#done-button'); await delayRandom(15000, 20000); // At this point, the video should be uploaded. The following code navigates to the newly uploaded video's page and leaves a comment. // Get the URL of the newly uploaded video const element = await page.$('#share-url'); const share = await page.evaluate(el => el.innerHTML, element); await page.goto(share); await delayRandom(10000, 15000); // Click the "Comments" button to expand the comments section await page.click('#comments-button'); await delayRandom(5000, 10000); // Press the "Tab" key several times to navigate to the comment text box await page.keyboard.press('Tab'); await delayRandom(1000, 2000); await page.keyboard.press('Tab'); await delayRandom(1000, 2000); await page.keyboard.press('Tab'); await delayRandom(1000, 2000); // Type the comment text into the text box await page.keyboard.type('Special prize for you: cpalinkhere', {delay: 150}); await delayRandom(1000, 2000); // Click the "Submit" button to post the comment await page.click('#submit-button'); await delayRandom(15000, 20000); // Print a message to indicate that the upload and comment posting are complete, and exit the script console.log('Upload completed') process.exit(); }) .catch(function(error) { console.error(error); //process.exit(); });